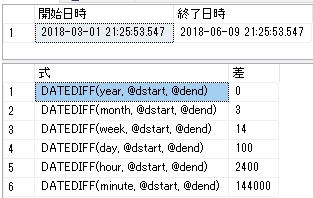
Windows 10 Microsoft アカウントとローカルアカウントの違い
Windows 10 は2種類のユーザーアカウントを使うことができます。
1つは、Microsoft アカウント
もう1つは、ローカルアカウント
ちなみに、Microsoft アカウントでサインインすれば、Microsoft が提供するさまざまなオンラインサービスが利用できるため、Windows 10では、Microsoftアカウントの使用が推奨されています。
この2つのユーザーアカウントの違いは何なのでしょうか?
2種類のユーザーアカウント
ローカルアカウントとMicrosoftアカウントについて少し説明します。
ローカルアカウント
使用するパソコンにアカウントを登録し、パソコンでサインイン(ログイン)認証を受けます。
パソコンにアカウントを登録するため、パソコン固有のアカウントになります。
複数のパソコンに同じアカウント名でアカウントを作成しても、もちろんパソコンの設定は同期されません。
また、ローカルアカウントでは、Microsoft Store からアプリをダウンロードすること、Microsoft が提供するオンラインサービスを使用したりすることができません。
Microsoftアカウント
Microsoft にアカウントを登録し、インターネット経由でサインイン認証を受けます。
Microsoftアカウントは、パソコンに電子メールアドレスとパスワードを使用して、Microsoft が提供するオンラインサービス( Outlook.com や OneDrive など)や Windows 10 へサインインするためのアカウントです。
Microsoftアカウントでサインインすると、Microsoft Store から任意のアプリをダウンロードすることができます。
また、複数のパソコンに同じMicrosoftアカウントでサインインすると、個人設定をオンラインで同期して、パソコンのテーマや壁紙、ブラウザーのお気に入り、アプリなどを共有できます。
会社などで急なPC変更があっても個人設定をオンラインで同期してくれるので、この機能は助かりますね。
どちらを選ぶ?
便利なのは Microsoft アカウントですね。私も基本 Microsoft アカウントを使っています。
Microsoft が提供するオンラインサービスにシームレスに繋がるので何かと便利です。
ただ、 Microsoft に管理されている感が残りますので、なんとなく不安と言う人も居ると思います。
Microsoft が提供するオンラインサービスを何も使っていなくて、PCも1台しか使っていない場合だと、ローカルアカウントで十分ですね。
ローカルアカウントなら個人情報も Microsoft に提供しなくて済みますしね。
ちなみに、 Microsoft アカウントもネットに接続していない OFF LINE 状態でも最後に使ったパスワードを使ってログインできるので、必ずネット接続していないとダメと言うわけではありません。
Microsoft アカウントとローカルアカウント、どちらを使っても大差ないので、Microsoft に管理されている感をあまり感じない人は Microsoft アカウントが便利だと思います。
気になる人は、個別管理のローカルアカウントで。
以上、「Windows 10 Microsoft アカウントとローカルアカウントの違い」でした。