
SQLSERVER EXISTS、NOT EXISTS
EXISTS と NOT EXISTS
サブクエリの導入にキーワード EXISTS を使用した場合、そのサブクエリは「存在検査」として機能します。
NOT キーワードを付けた場合、そのサブクエリは「非存在検査」として機能します。
サブクエリの WHERE 句では、
・ データ抽出されるテーブル と 存在を試されるテーブル との リンク条件を指定します。
・ 存在を試されるテーブル の検索条件を指定します。
このことにより、このサブクエリから返される行が存在するかどうかがテストされます。
サブクエリは実際にはデータを生成せず、TRUE または FALSE の値を返します。
WHERE [NOT] EXISTS (subquery)
EXISTS演算子とは
EXISTS 演算子は、副問い合せの結果が存在するかを調べるときに使用します。
このとき、副問い合せの結果が存在するとき真になります。
NOT EXISTS演算子とは
NOT EXISTS 演算子は、副問い合せの結果が存在しないかを調べるときに使用します。
このとき、副問い合せの結果が存在しないとき真になります。
EXISTS、NOT EXISTS のテストサンプル
以下にテストSQLを載せておきます。
@tbl1には、id,kbn,pointの三項目
@tbl2には、id,kbn,priceの三項目
point,priceはランダムで数値が入ります。
@tbl1 と @tbl2は、同じid(kbnも)が入ります。
@tbl2のpriceの条件に合わせて、存在する存在しないをテストし、@tbl1のレコードを取得しています。
declare @tbl1 table(
id int,
kbn nchar(10) ,
point int
)
declare @tbl2 table(
id int,
kbn nchar(10) ,
price int
)
declare @start_id as int
set @start_id=0
while @start_id < 10
begin
print @start_id
insert into @tbl1 values(@start_id, @start_id % 3, @start_id * Rand() * 10)
insert into @tbl2 values(@start_id, @start_id % 3, @start_id * Rand() * 100)
set @start_id = @start_id +1
end
select * from @tbl1
select * from @tbl2
/* EXISTS */
/* テーブル@tbl2のpriceが200より大きなレコードを取得し、@tbl1の該当するレコードを表示する*/
select * from @tbl1 t1
where EXISTS (
select * from @tbl2 t2
where t1.id= t2.id --レコードのリンク
and t2.price >= 200 --条件
);
/* NOT EXISTS */
/* テーブル@tbl2のpriceが200より大きなレコードを取得し、@tbl1の該当しないレコードを表示する*/
select * from @tbl1 t1
where NOT EXISTS (
select * from @tbl2 t2
where t1.id= t2.id --レコードのリンク
and t2.price >= 200 --条件
);
IN 句と INNER JOIN 句 と比較
ちなみに、EXISTはINよりも速いとか、EXISTSは INNER JOIN より遅いだとか、良く耳にしますが、実際どうなんでしょうね?
個人的には、条件や状況によって違うのではないかと考えています。
Indexの有無、テーブルの大きさ、暗黙的な変換の有無、直前に使用テーブルにアクセスしてた等々条件や状況によって変わってくると。
とりあえず簡単なパフォーマンステストをしてみたいと思います。
サンプルSQLは以下の通りです。
自前の環境で、条件を変えてテストしてみてください。
create table #tbl1 (
id int,
kbn nchar(10) ,
point int
)
create table #tbl2(
id int,
kbn nchar(10) ,
price int
)
--create index #idx2 on #tbl2(price);
declare @start_id as int
set @start_id=0
while @start_id < 100000
begin
print @start_id
insert into #tbl1 values(@start_id, @start_id % 3, @start_id * Rand() * 10)
insert into #tbl2 values(@start_id, @start_id % 3, Rand() * 1000)
insert into #tbl2 values(@start_id, @start_id % 3, Rand() * 1000)
insert into #tbl2 values(@start_id, @start_id % 3, Rand() * 1000)
set @start_id = @start_id +1
end
--select * from #tbl1
--select * from #tbl2 where price >= 900
--ここからテスト
/* EXISTS 句でパフォーマンステスト */
print CONVERT(VARCHAR, GETDATE(), 114)
select * from #tbl1 t1
where EXISTS (
select * from #tbl2 t2
where t1.id= t2.id --レコードのリンク
and t2.price >= 900
)
print CONVERT(VARCHAR, GETDATE(), 114)
/* IN 句でパフォーマンステスト */
print CONVERT(VARCHAR, GETDATE(), 114)
select * from #tbl1 t1
where t1.id IN (
select t2.id from #tbl2 t2
where t2.price >= 900
)
print CONVERT(VARCHAR, GETDATE(), 114)
/* join 句でパフォーマンステスト */
print CONVERT(VARCHAR, GETDATE(), 114)
select distinct t1.* from #tbl1 t1
inner join #tbl2 t2
on t1.id=t2.id
where t2.price >= 900
print CONVERT(VARCHAR, GETDATE(), 114)
/* drop table */
/*
drop table #tbl1
drop table #tbl2
*/
ここでまず、INDEX無のEXISTS,IN,INNER JOINのそれぞれの実行プランを確認してみます。
EXISTS句
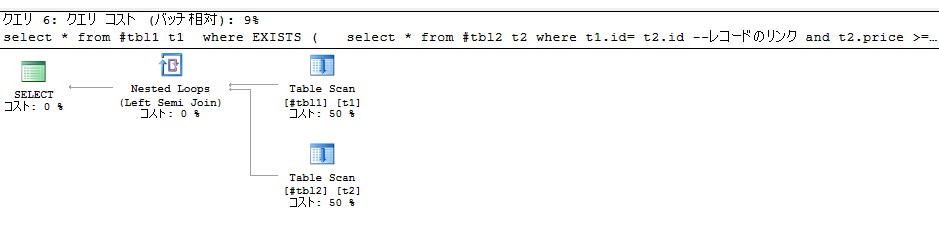
EXISTS句-パターン1INDEX無の実行プラン
クエリコストがバッチ相対で9%になっています。
IN句

IN句-パターン1INDEX無の実行プラン
EXISTS句と同じくクエリコストがバッチ相対で9%になっています。
INNER JOIN句
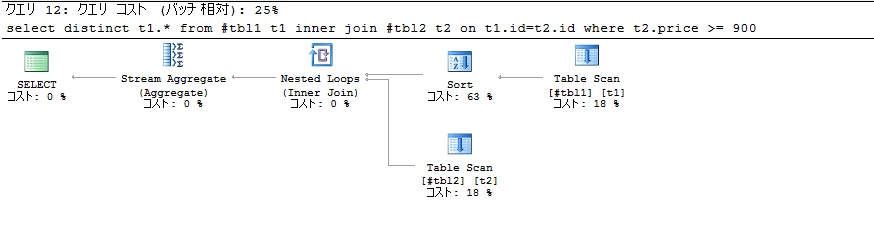
INNER JOIN句-パターン1INDEX無の実行プラン
クエリコストがバッチ相対で25%になっています。
実行して試してみます。
ただし一度メモリに読み込まれてしまうと、最適化された状態で動くことになるので、実際のパフォーマンスとはかなり異なります。
もし、少しでも正確に行いたいのなら、テーブルを毎回作り直して、初回で比較する方が良いと思われます。
今回はメモリに展開したうえでのパフォーマンス比較を行っています。各々2回図ります。
参考:ど初回、EXISTS句
開始:07:52:12:613
終了:07:52:14:300
結果:1687ms
—–ここから
初回:EXISTS句
開始:08:01:44:583
終了:08:01:46:287
結果:1704ms
初回:IN句
開始:07:58:20:097
終了:07:58:21:690
結果:1687ms
初回:INNER JOIN句
開始:08:07:10:097
終了:08:07:12:363
結果:2266ms
2回:EXISTS句
開始:08:08:32:600
終了:08:08:33:927
結果:1327ms
2回:IN句
開始:08:05:31:440
終了:08:05:33:160
結果:1720ms
2回:INNER JOIN句
開始:08:03:56:490
終了:08:03:57:973
結果:1483ms
なんとも締まらない結果になってしまいました。
10万件では少なかったかな。。。
とりあえず、次はpriceにIndexを貼ってやってみます。
でも実行プランも変わらなかったので、priceにIndexを貼っても効果ないようです。
どこにどう貼れば効果あるのかな・・・
ちなみに、Indexを貼るのに10秒かかりました。
初回:EXISTS句
開始:08:13:15:660
終了:08:13:17:647
結果:1987ms
初回:IN句
開始:08:15:48:677
終了:08:15:50:520
結果:1843ms
初回:INNER JOIN句
開始:08:14:47:300
終了:08:14:49:130
結果:1830ms
2回:EXISTS句
開始:08:16:37:147
終了:08:16:38:270
結果:1123ms
2回:IN句
開始:08:18:28:660
終了:08:18:29:833
結果:1173ms
2回:INNER JOIN句
開始:08:17:32:973
終了:08:17:34:647
結果:1674ms
Indexを貼っても有効に機能しなかったので結果は同じでしたね。
簡単なテーブルではパフォーマンスに差も出ないようですね。
じっくり検討すれば早くなる可能性もありますが、とりあえず簡易テストの結果、それほどの差は出ないということでした。
以上、簡単なサンプルでの説明でしたが、SQL SERVER EXISTS、NOT EXISTS についてでした。