まず、「Noto Sans」と言うGoogleとAdobeが共同開発したフォントファミリーがあります。その中でWebで簡単に使えるのが、「Noto Sans Japanese」と「Noto Sans JP」フォントになります。他にも「Noto Sans CJK JP」フォントとかも有るのですが、Webでは「Noto Sans Japanese」と「Noto Sans JP」が使いやすいです。
Noto Sans Japanese と Noto Sans JP はGoogle fontsとして公開されていますが、Noto Sans Japanese はベータ版として認識されているようです。あとは、フォントの太さの段階(Weight)が7段階か6段階の違いがあります。下の表のようになっています。
SET NUMERIC_ROUNDABORT OFF;
SET ANSI_PADDING, ANSI_WARNINGS, CONCAT_NULL_YIELDS_NULL, ARITHABORT,
QUOTED_IDENTIFIER, ANSI_NULLS ON;
--従業員テーブルの作成とデータ挿入
create table EMPLOYEE_V (
EMPLOYEE_ID nchar(5)
, NAME nvarchar(20) NOT NULL
, KANANAME nvarchar(20)
, BATHDAY DATE
, SEX nchar(1)
, JOIN_DATE DATE
, POST_CODE nchar(7)
, ADDRESS nvarchar(100)
, TEL nvarchar(11)
)
insert into [dbo].[EMPLOYEE_V] values('T0001','太郎','タロウ','1997-08-2','1','2013-03-30','2005347','住所','09001239876')
insert into [dbo].[EMPLOYEE_V] values('T0002','花子','ハナコ','1997-08-2','1','2013-03-30','2005347','住所','09001239876')
insert into [dbo].[EMPLOYEE_V] values('T0003','次郎','ジロウ','1997-08-2','1','2013-03-30','2005347','住所','09001239876')
insert into [dbo].[EMPLOYEE_V] values('T0004','三郎','サブロウ','1997-08-2','1','2013-03-30','2005347','住所','09001239876')
--部門テーブルの作成とデータ挿入
create table BUMON_V(
BUMON_CD nchar(3)
, BUMON_NAME nvarchar(20)
, primary key CLUSTERED (BUMON_CD)
)
insert into [dbo].[BUMON_V] values('001','営業部')
insert into [dbo].[BUMON_V] values('002','業務部')
insert into [dbo].[BUMON_V] values('003','製造部')
insert into [dbo].[BUMON_V] values('004','総務部')
--配属テーブルの作成とデータ挿入
create table HAIZOKU_V(
EMPLOYEE_ID nchar(5)
, START_DATE date
, END_DATE date
, BUMON_CODE nchar(3)
, primary key CLUSTERED (EMPLOYEE_ID, START_DATE)
)
insert into [dbo].[HAIZOKU_V] values('T0001','2019/04/02','2020/06/09','004')
insert into [dbo].[HAIZOKU_V] values('T0002','2020/04/02','2020/06/09','002')
insert into [dbo].[HAIZOKU_V] values('T0003','2020/04/02',null,'002')
insert into [dbo].[HAIZOKU_V] values('T0004','2020/04/02',null,'002')
insert into [dbo].[HAIZOKU_V] values('T0001','2020/06/10',null,'001')
insert into [dbo].[HAIZOKU_V] values('T0002','2020/06/10',null,'003')
GO
--Viewの作成
create View dbo.View_HAIZOKU
with schemabinding
as
select TH.EMPLOYEE_ID
, TH.BUMON_CODE
, TB.BUMON_NAME
, TE.NAME
, TE.KANANAME
from dbo.HAIZOKU_V TH
inner join dbo.EMPLOYEE_V TE on TH.EMPLOYEE_ID = TE.EMPLOYEE_ID
inner join dbo.BUMON_V TB on TH.BUMON_CODE = TB.BUMON_CD
where TH.end_date is null
GO
--インデックの作成(従業員ID)
create UNIQUE CLUSTERED index IDX_View_HAIZOKU
on View_HAIZOKU (EMPLOYEE_ID)
GO
--インデックの作成(部門コード)
create NONCLUSTERED index IDX_View_HAIZOKU2
on View_HAIZOKU (BUMON_CODE)
GO
--ビューからデータを取得
select BUMON_NAME
, NAME
, KANANAME
from View_HAIZOKU
order by BUMON_CODE
/*
drop view View_HAIZOKU
drop table EMPLOYEE_V
drop table BUMON_V
drop table HAIZOKU_V
*/
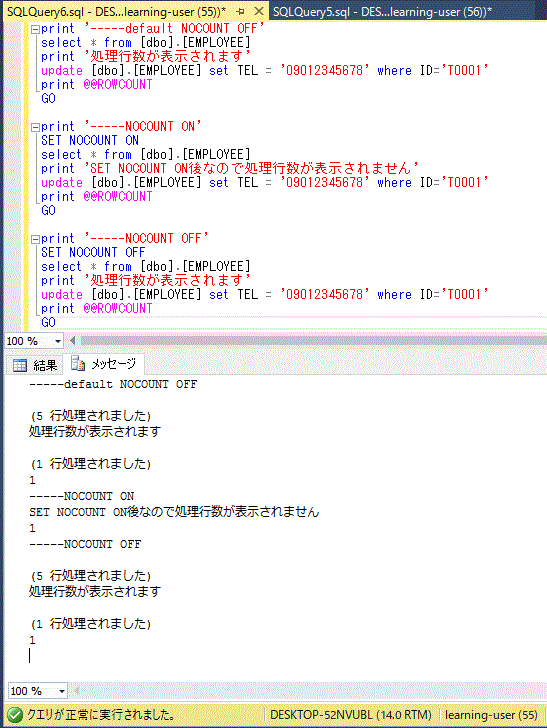
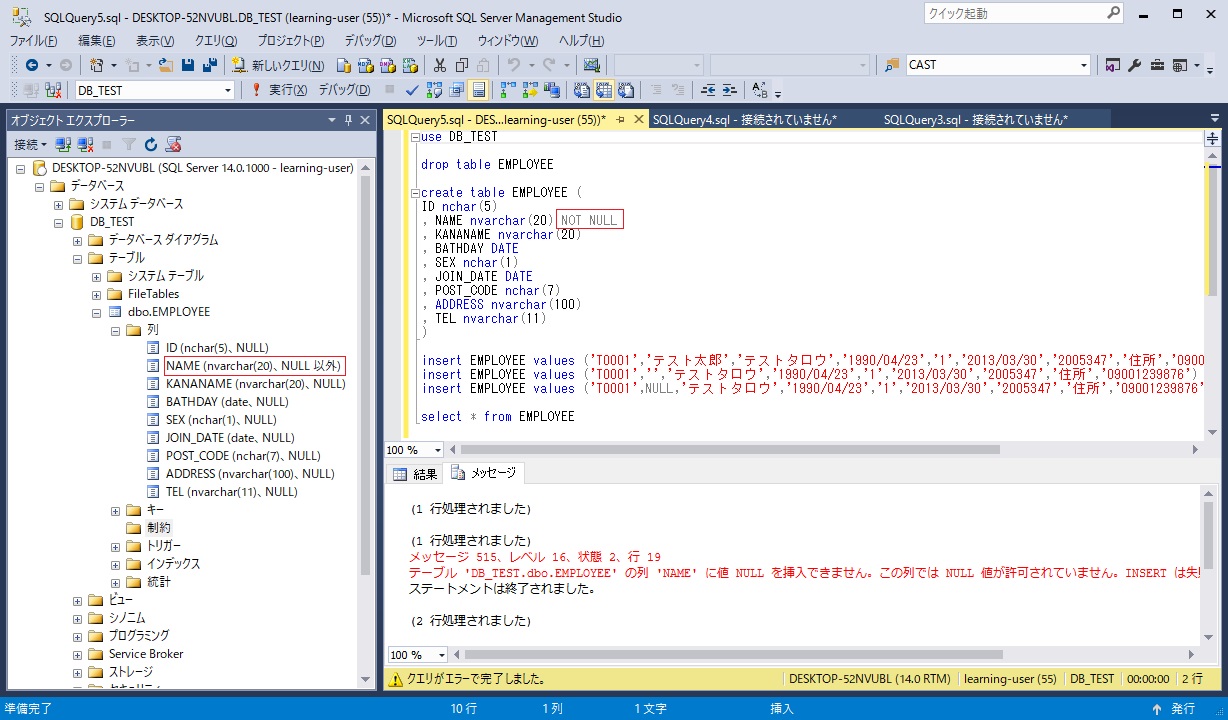
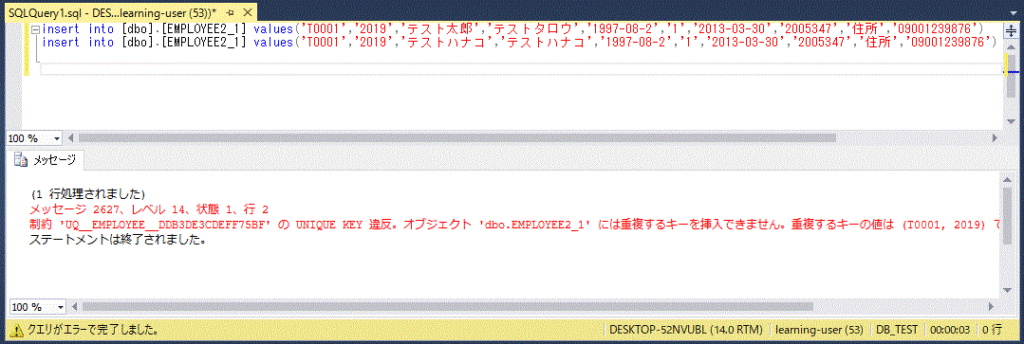
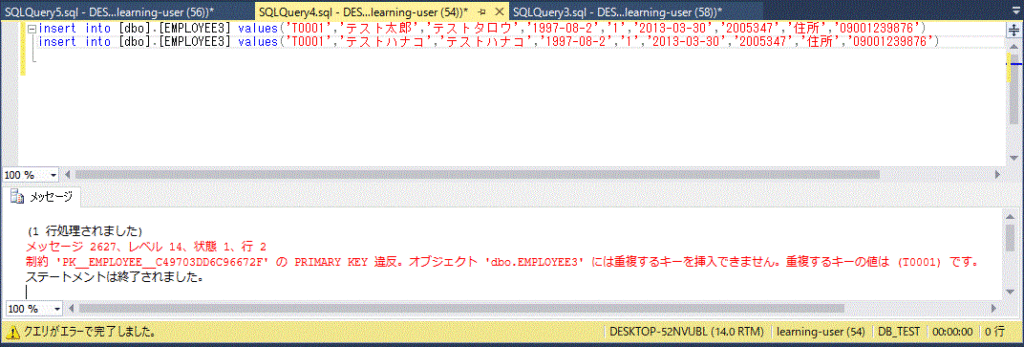
例えば上の EMPLOYEE テーブルにおいて、従業員の「NAME」の定義を NAME nvarchar(20) NOT NULL と指定し、「NAME」列のデータには必ず値を入れないと追加・更新できなようにします。
create table EMPLOYEE (
ID nchar(5)
, NAME nvarchar(20) NOT NULL
, KANANAME nvarchar(20)
, BATHDAY DATE
, SEX nchar(1)
, JOIN_DATE DATE
, POST_CODE nchar(7)
, ADDRESS nvarchar(100)
, TEL nvarchar(11)
)
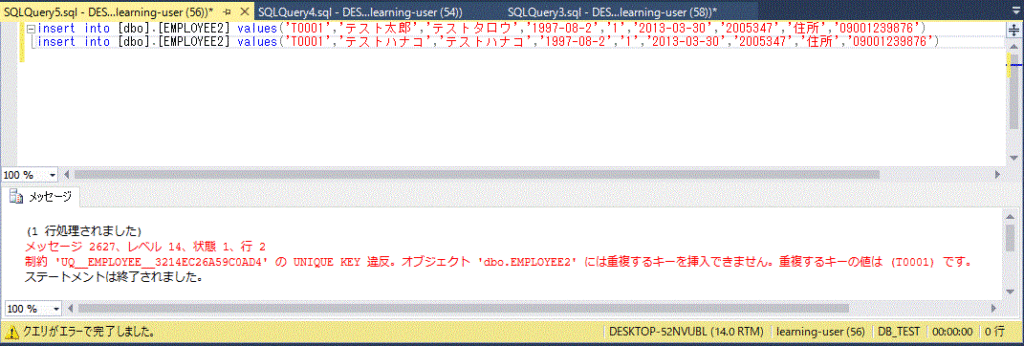
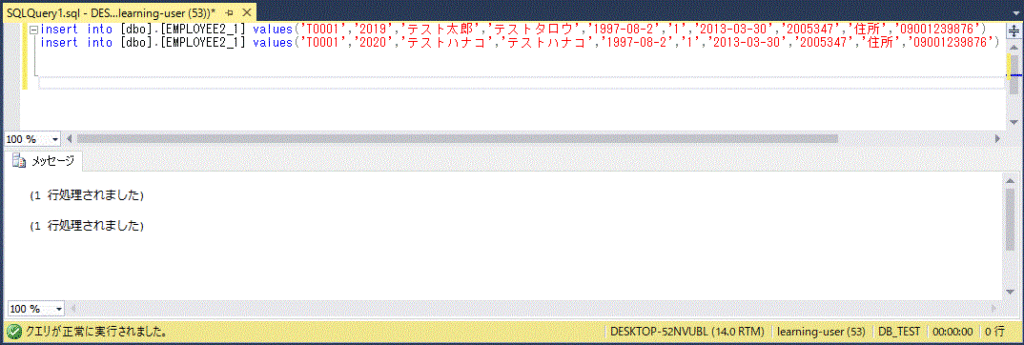
create table EMPLOYEE2 (
ID nchar(5) UNIQUE
, NAME nvarchar(20) NOT NULL
, KANANAME nvarchar(20)
, BATHDAY DATE
, SEX nchar(1)
, JOIN_DATE DATE
, POST_CODE nchar(7)
, ADDRESS nvarchar(100)
, TEL nvarchar(11)
)
・列名1 > 10 ・列名1 in (, , ,) ・列名1 between x and z ・列名1 > 10 AND 列名2 in (‘A’,’B’,’C’)
create table EMPLOYEE5_1 (
ID nchar(5)
, YYYY nchar(4)
, NAME nvarchar(20) NOT NULL
, KANANAME nvarchar(20)
, BATHDAY DATE
, SEX nchar(1)
, JOIN_DATE DATE
, POST_CODE nchar(7)
, ADDRESS nvarchar(100)
, TEL nvarchar(11)
, check (YYYY between '2010' and '2022')
)
check (YYYY in (select YYYY from [dbo].[YYYY4_1])) のような使い方はできません。『このコンテキストではサブクエリは許可されません。スカラー式だけが許可されます。』とエラーになります。
以上、「SQL Server Create Table」でした。
尚、SQL Server にはデータベースを作成するとき、複数のストレージに渡って作ることができます。HDD(ハードディスク)の個数でパフォーマンスが変わってくるので、大規模システムでは複数のストレージを使うことが多いです。 そして、ストレージ毎にファイルグループを持つように設定し、ストレージを分けることで負荷分散を行います。 このファイルグループにそれぞれ名前を付けることができます。 デフォルトはPRIMARYで、後は任意に名前を付けられます。
テーブルやインデックを作る時に「on」指定でこのファイルグループを指定できます。 この辺りは基礎ではないので私も詳しく説明できませんが、知っておくことは大切ですので、追記しておきます。詳しく知りたい人は「SQL Server Create table on」で検索するといろいろ出てくると思います。検索してないので……多分。
無料のEXCELで作りましたので、EXCELを持っていなくても、「無料の Web 版 Office で作成、共有、コラボレーション」でEXCELを使えるようにすれば、疑似偏差値を使えるようになります。無料のWeb版Officeを使えるようになる方法がわからなけくても、検索すればすぐにその方法がわかると思います。