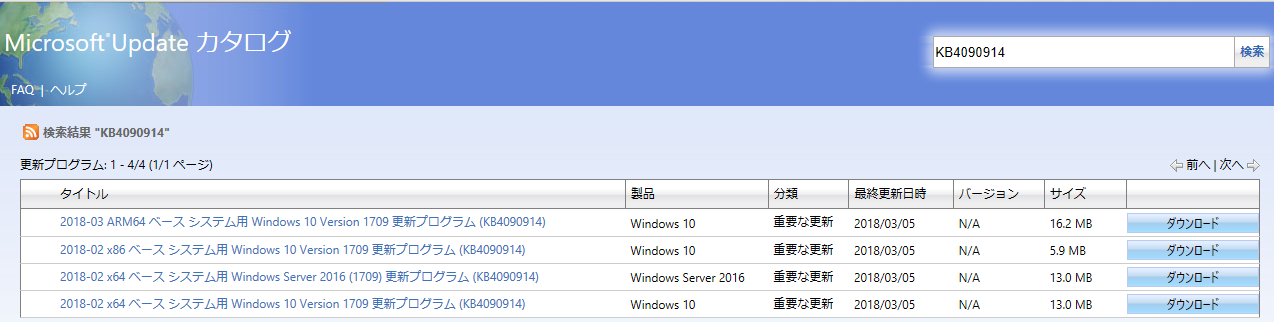
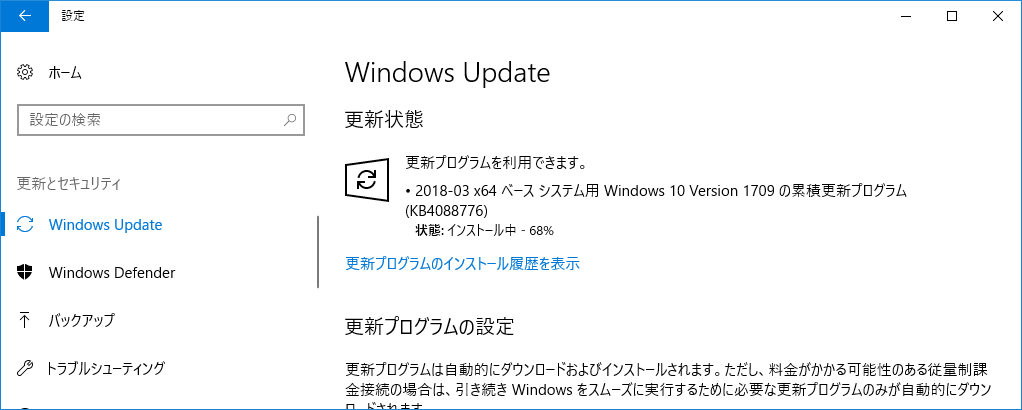
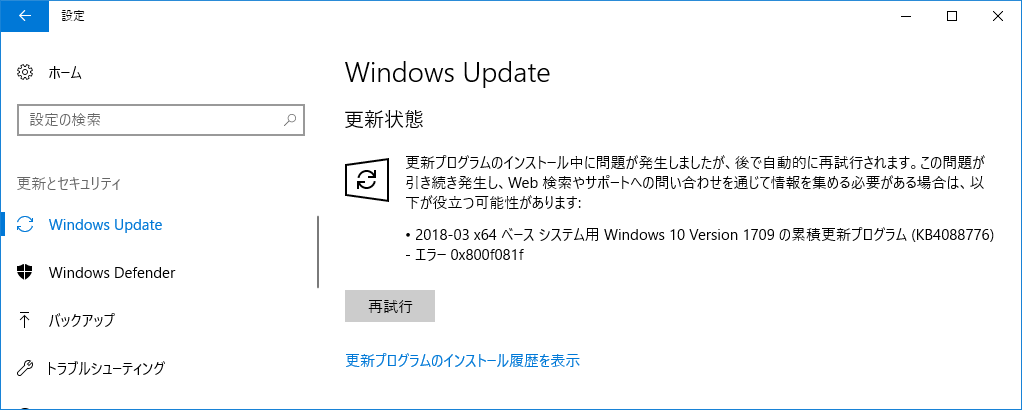
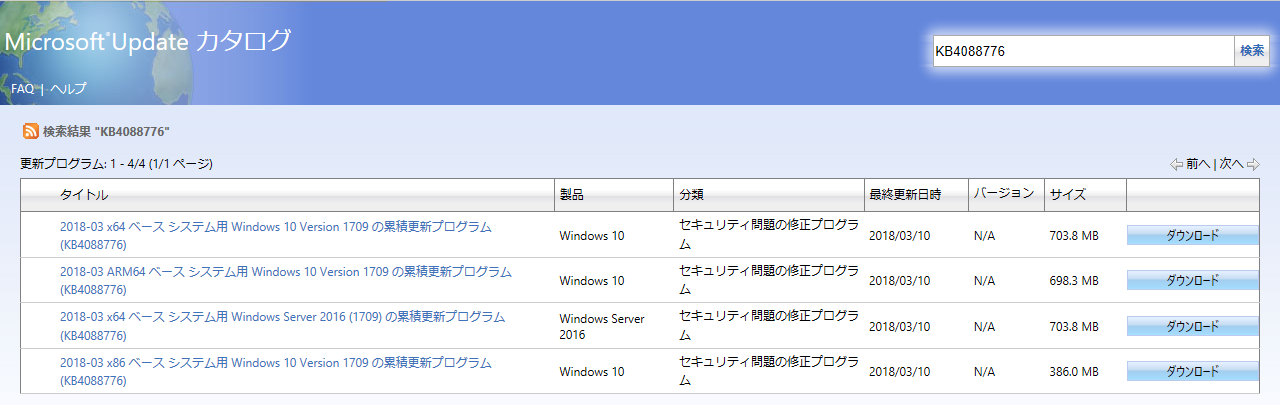
Windows 10 起動が遅い時の対処方法
最近、昔使っていたノートPCのメモリを増やして活用しています。
が、やはりとっても重くて。。。
一番の原因はWindows Update なのですが、これは仕方ないので重くても放置して、我慢しています。
起動時に重くなる原因はその他にもいくつかあるので、ここで原因とその対処法を紹介していきます。
・Windows SuperFetch
・Microsoft compatibility telemetry
今のところ、2つが目立っているので、この2つから。
起動が遅い時・重い時の確認方法
ちなみに、起動が遅い時や立ち上げ直後はアプリが重いとか、そんな時は「タスクマネージャー」で重くなっている原因を確認しましょう。
タスクマネージャーの立ち上げ方はいくつかありますが、スタートボタンを右クリックすると下のようなメニューが表示されますので、その中からタスクマネージャーをクリックします。
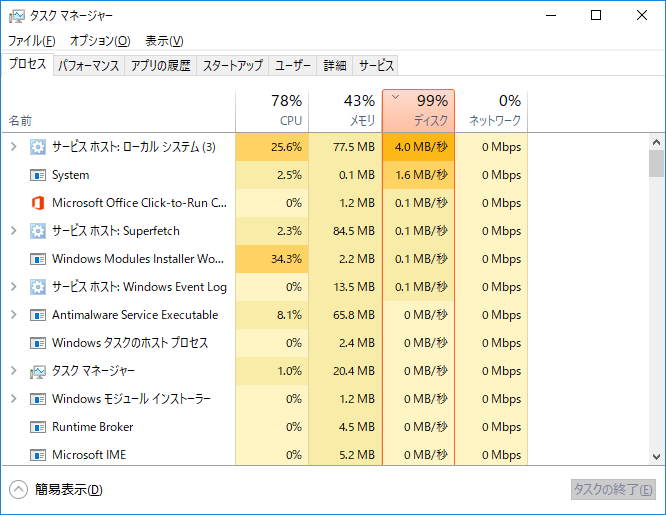
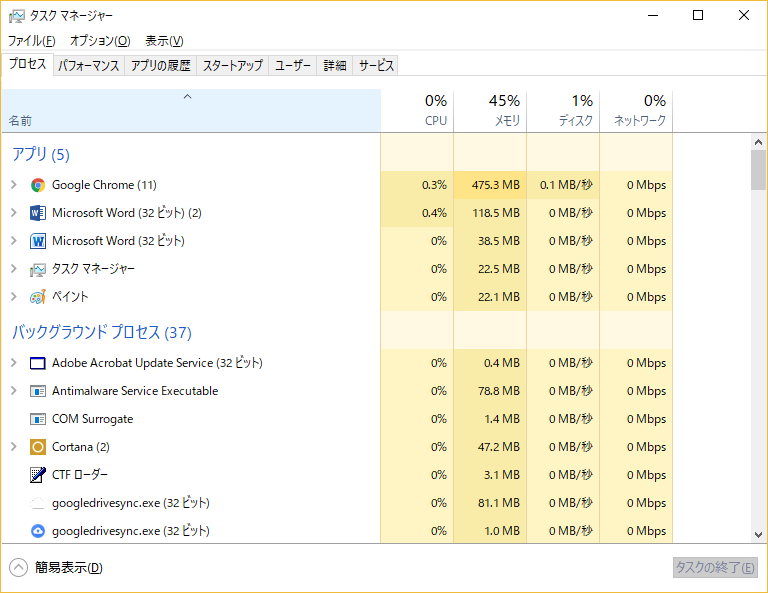
タスクマネージャーを立ち上げると、下の画面にいなります。
[プロセス]タブでは、どのプロセスがCPU,メモリ,ディスク,ネットワークをどの程度使用しているのかがわかります。
中にはサービスホスト:ローカルシステム(x)のようにまとめて表示されるものあります(32bit版)が、[>]をクリックすると展開されて何が起動されているかだけわかります。
立ち上げ時やいつもと違って重いと感じたときは、タスクマネージャーでどんなプロセスが重たくしているかを確認しましょう。
タスクマネージャーの見方
CPUやメモリ,ディスクが100%になっていると、PCの動作が緩慢になります。
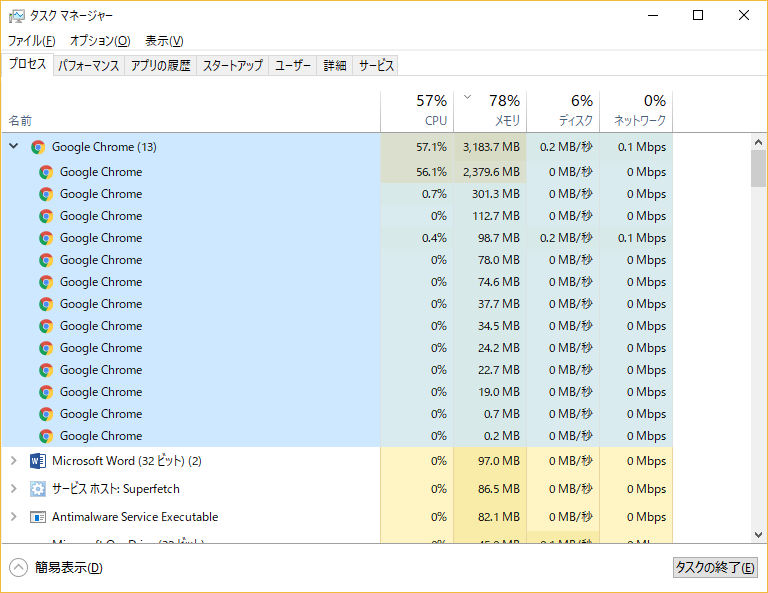
上の図では、Google Chrome がメモリを475.3MB使っています。他のプロセスやアプリも合わせて全体の45%のメモリを使用しています。
これがメモリ100%に近いと、メモリのスワップという動作が起こり、ディスクにも影響を及ぼしかなりPCの動作を重くします。
そんな場合は、メモリをたくさん使っているアプリを終了させメモリを100%使用状態から救い出すことで動作が軽くなります。
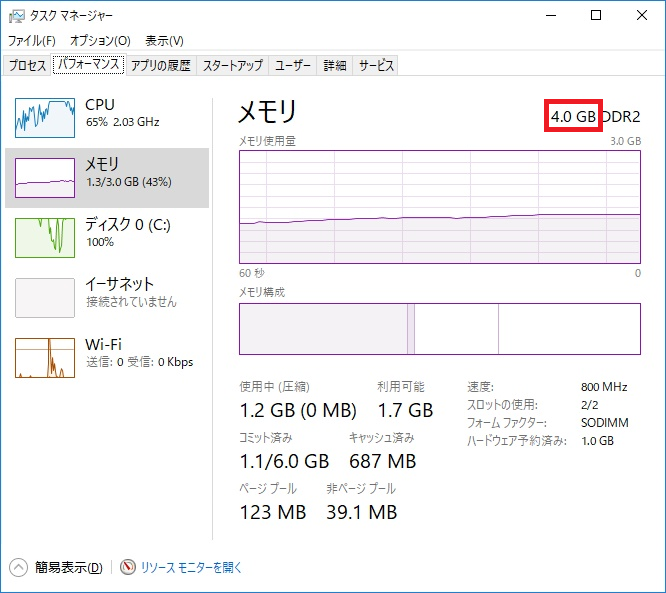
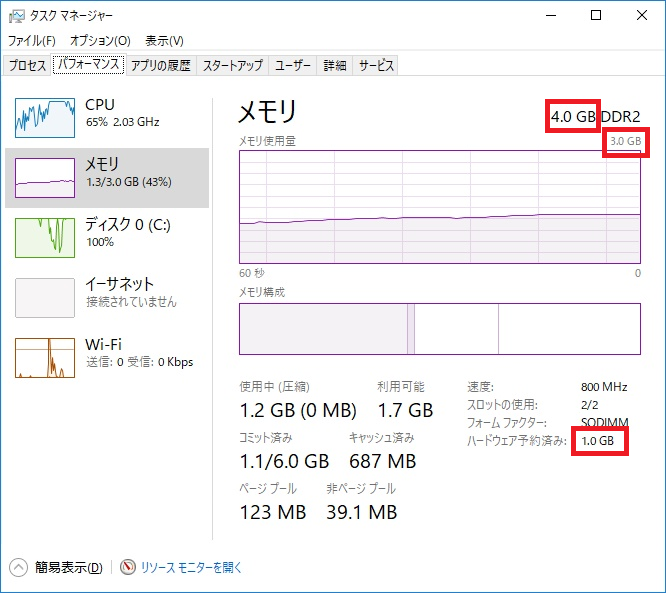
また、メモリのスロットに空きがあるとか、メモリ容量の小さなメモリを使っている場合には、メモリ容量を追加することでメモリ100%使用状態から抜け出すことも出来ます。
しかし、以下のような場合も有り突然にPCが重たくなることも。。。
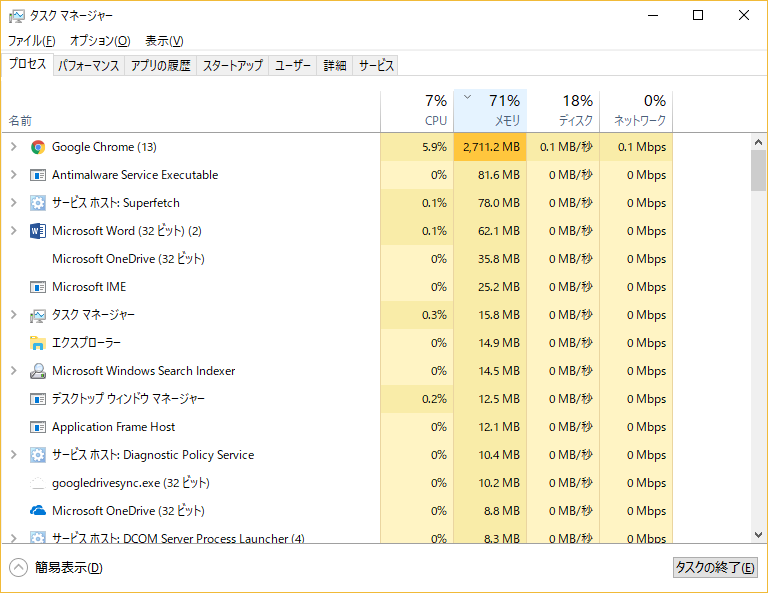
その後、何も触ってないのにGoogle Chrome がメモリを2,711.2MBまで使い始めました。
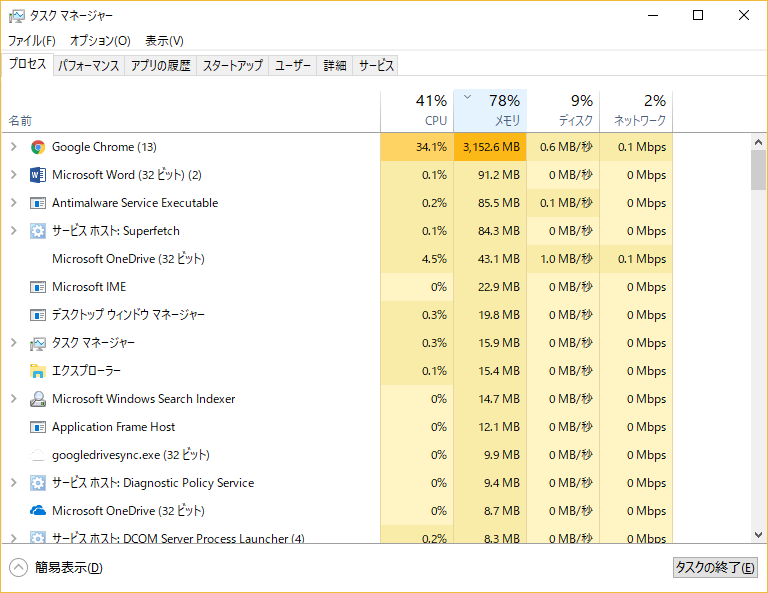
その後、3,152.6MBへ。何がGoogle Chromeを駆り立てているのでしょう??
3GBは勘弁して欲しい。。。
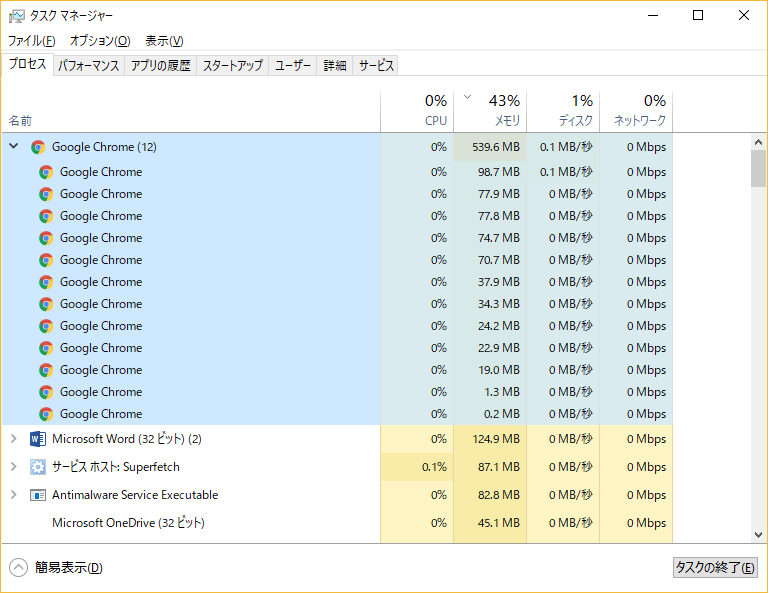
しばらくすると落ち着きました。
なにもしていないのに、プロセス(タスクかな?)が13から12に減っていました。
Google Chrome なにか勝手にやってくれます。
このように、突発的な事象もタスクマネージャーでは見られて、対応できることなら対応する目安になります。
上のGoogle Chrome の場合は、Chrome を停止すれば解消されるのでしょうが、そのうちまたやりだすので Chromeを使うのをやめるしか手がないかも知れません。私は便利なのでChrome を使い続けますけど。
CPUが100%に近い場合は、処理が終わるのを待つしかありません。
無駄なアプリを動かしているのなら終了させることも出来ますが、そうでない時は待つしかありません。
CPUは稼働しているプロセスやアプリのみ使用しているのでメモリのように稼働していないアプリを終了させても効果は望めません。
CPUが常に100%に近い場合は、CPUの上位機種に変えることがもっとも有効です。
ディスクが100%に近い場合も処理が終わるのを待つしかありません。
CPUと同じく無駄なアプリを動かしているのなら終了させることも出来ますが、そうでない時は待つしかありません。
ディスクが100%に近い場合は大量のデータアクセス時、Windows Updateや動画再生・編集なので、常に100%であることは無いと思います。
それでも何とかしたい場合は、SSD(ソリッドステートドライブ)に変えるとか手も有りますので検討をしてください。
ざっくりとですが、以上のようにどのようにしたら良いかの目安になりますのでタスクマネージャーを活用しましょう。
ここでの対処対象
ここで紹介する対処対象は、有っても無くてもさほど関係ないけど重たくする原因となるプロセスです。
起動時はいろいろなアプリが一斉に活動するため遅くなっても仕方のないこと何のですが、起動後の落ち着いた時間帯に少し速くなるために起動直後の大変な時に負荷をかけるプロセスはメリットが小さいので機能を停止させておきましょうという趣旨です。
例えば「Windows SuperFetch」は、アプリケーションの起動速度の向上、全体的なレスポンスの向上、空きメモリの有効活用が見込めますが、逆に立ち上げ時はその下準備のためにやたらディスクやCPUを使い起動を遅くするなど弊害があります。
私は古いPCに Windows SuperFetchのメリットを感じないので機能を停止させます。
各々のPCの能力とおメリットデメリットに合わせて、停止の対象にするか検討してください。
今後、古いPCを使っていて重いかなと思った時に確認してご紹介していきます。
以上、「Windows 10 起動が遅い時」の対処方法のご紹介まで。