そば粉(蕎麦粉)の不思議
何が不思議かって言うと、そば(蕎麦)について書いてあるホームページで違う説明があることです。
製粉メーカー、蕎麦屋、食べ歩きブログ?などプロやセミプロと思われる人々の間で異なるって結構な齟齬ですよね?
調べようと思った切っ掛けは、蕎麦好きの人は割と周りに居ますが、一番粉、二番粉、三番粉のことや、更科、藪のことも曖昧な人の多いこと多いこと。
そこで気になってしまい、調べてみたところ、ウィキペディア(Wikipedia)では、以下の通りに説明されていました。
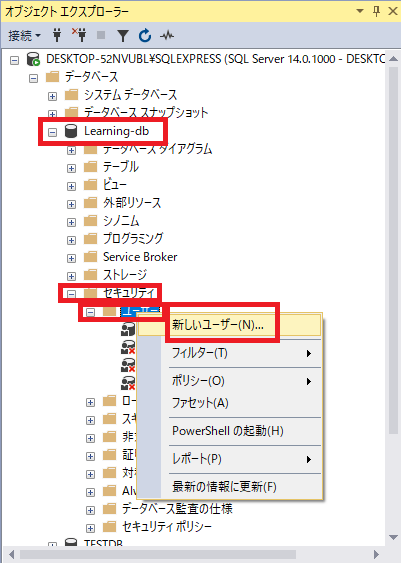
蕎麦粉
◆一番粉
内層粉、そばの実の中心部分の胚乳のさらに中心部が主体、白色でほのかな甘みがある最上級粉だがそば独特の香りや風味に欠ける。成分は主に炭水化物(でんぷん)と水分。更科粉(さらしなこ)とも呼ばれることがあるが、本来の更科粉は製法が異なる。
◆二番粉
中層粉、胚乳と子葉(胚芽)の一部が主体、うす緑黄色で香りが高く風味に優れる。ちゅうそう粉と表記されることも多い。
◆三番粉
表層粉、胚乳の一部と子葉(胚芽)と種皮(甘皮)の一部、やや暗い青緑色で香りが強く栄養価が高いが味と食感に劣る。
◆末粉
表層粉、子葉(胚芽)と種皮(甘皮)が主体、黒っぽくホシ(甘皮や蕎麦殻の破片)が多い。風味は非常に強いが食感は最も劣る。栄養価は最も高い。蕎麦がきや蕎麦菓子、冷凍麺、ゆで麺、乾麺の色づけなどに使用。四番粉、五番粉とも。特に繊維や殻の破片が多いものはさな粉(さなご)とも呼ばれる。
ちなみに、脱皮など綺麗にして、石臼挽き⇒篩いがけ(一番粉)⇒石臼挽き⇒篩いがけ(二番粉)⇒石臼挽き⇒篩いがけ(三番粉)⇒石臼挽き⇒篩いがけ(末粉)のように、間に石臼挽きが入ります。
特に「藪そば」「挽きぐるみ」については言及がありません。
一番粉、二番粉、三番粉などについては各ホームページにも特に詳しく載っておらず、更科粉の製法に簡易方法?が有るぐらいでホームページ間の齟齬もありません。
さてさて、藪そばに使うそば粉ですが・・・
日本製粉グループ松屋製粉株式会社さんのホームページでの「そば粉説明」では、

「藪そば」は、「三番粉」
「挽きぐるみ」は、「二番粉」
となっています。
TOKYO SOBA NIGHT SOBARさんのホームページでの「そば粉説明」では、

「藪そば」は、「一番粉と二番粉を併せて打ったお蕎麦」
「挽きぐるみ」は、「一番粉、二番粉、三番粉全てが含まれるソバ粉」
となっています。
東京にある『表参道でお蕎麦を味わうなら、「しろう」』さんの説明では、

「藪そば」は、「藪蕎麦に使われる蕎麦は二番粉・三番粉を使った風味の強い蕎麦」
となっています。
いやいや、そば(蕎麦)は奥深いですね。
「藪そば上手いねぇ・・・
ここ『藪そば』は、
一番粉と二番粉を併せて打ったお蕎麦?
それとも三番粉?
はたまた二番粉・三番粉を使ってるの?
あはは、美味けりゃ何でも良いか(^-^)」
興味のある方は更に調べてみてください。なかなかに奥深い・・・です。
ふと思った「そば粉(蕎麦粉)の不思議」でした。
とっても久しぶりの投稿が変な疑問で申し訳ない(^^;)