SQL Server Management Studio (SSMS) とは
SSMS(SQL Server Management Studio) は、SQL Server や Azure SQL Database の SQL インフラストラクチャを管理するための統合環境です。
SSMS には、SQL のインスタンスを構成したり、状況を監視したり、データベースを管理するためのツールが備わっています。
SSMS を使用して、アプリケーションで使われるクエリとスクリプトを作成したりすることもできます。
SSMSを利用すると、データベースがローカル コンピューター上にあっても、ローカルネットワーク上にあっても、クラウドにあっても、どこにあっても作業ができます。
SSMS は無料です。
SSMS の入手
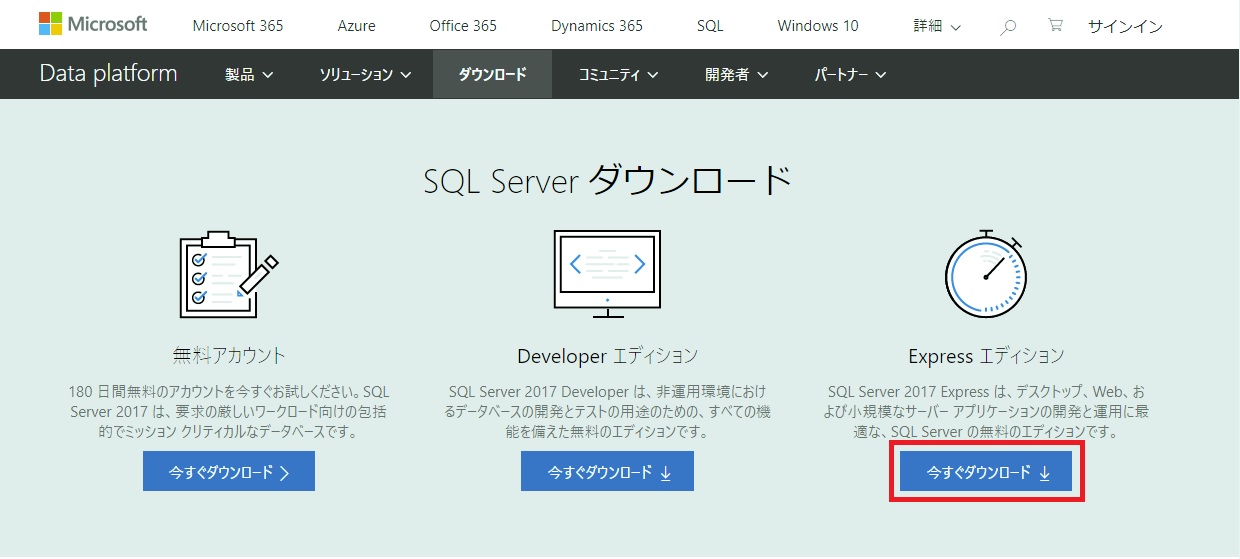
SSMSはマイクロソフトからダウンロード可能です。
SSMS ダウンロード で検索すると一番上に出てくると思いますので、ダウンロードしてインストールしてください。
インストールは他のWebサイトに詳しく書いてあると思うので、各自でググってください。
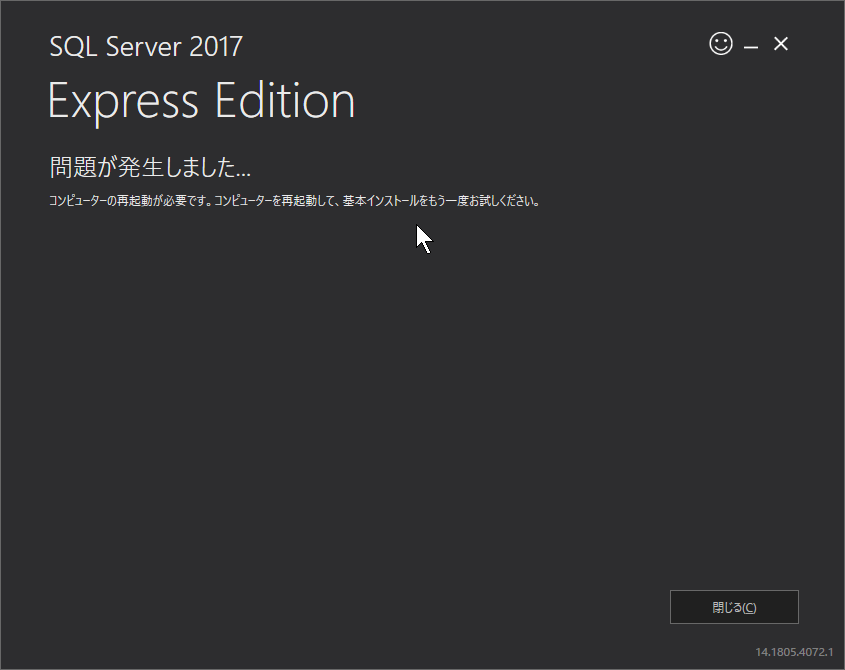
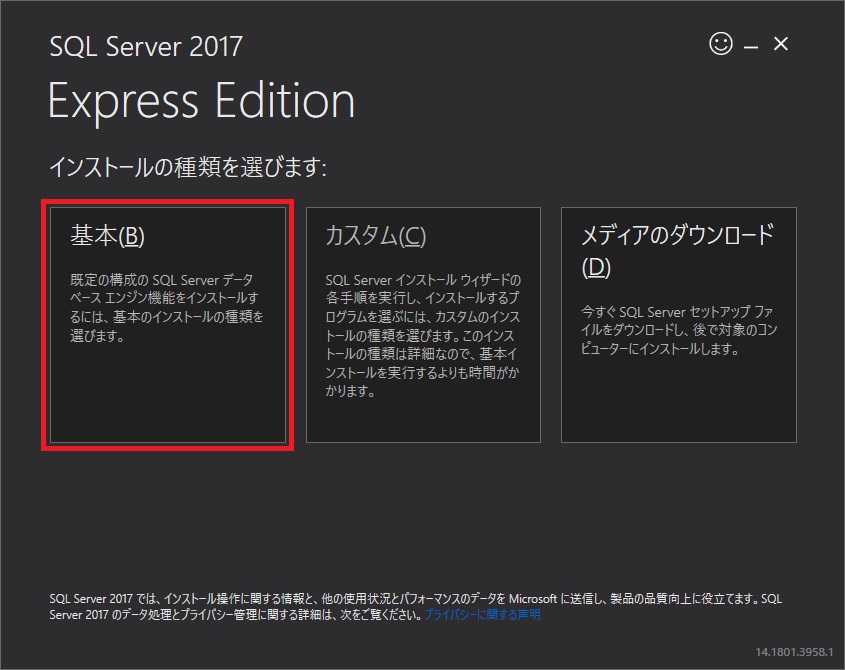
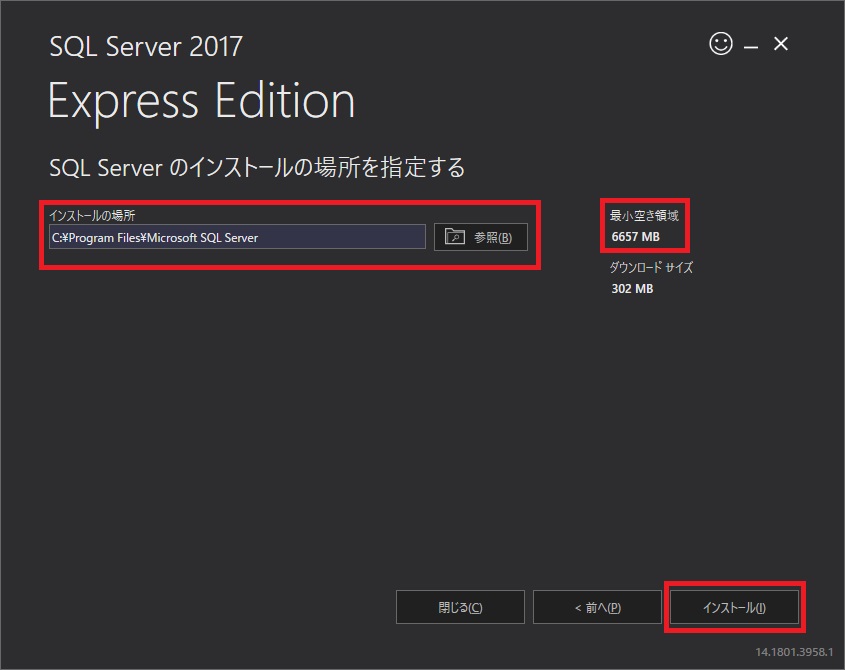
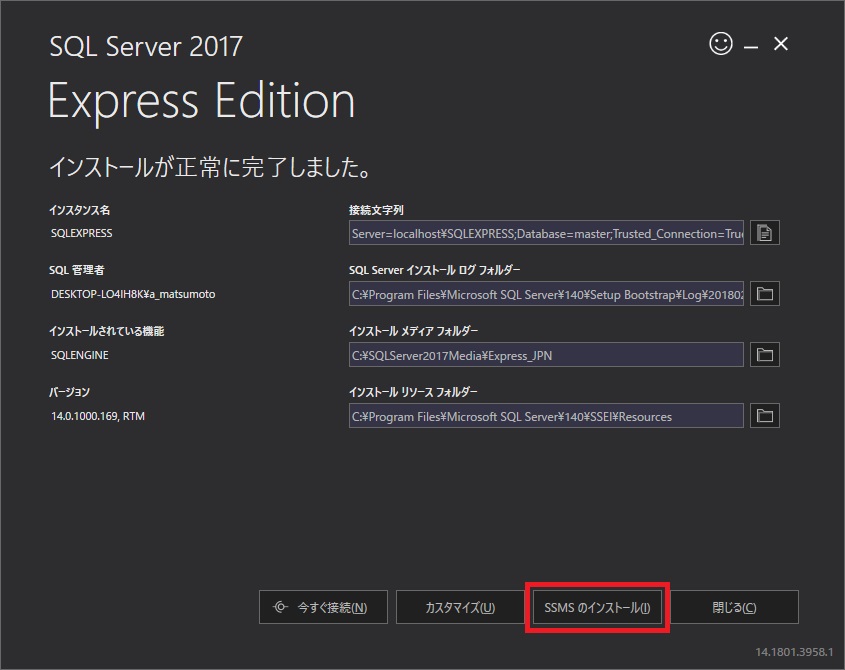
このWebサイトにも「SQL Server 2017 Express エディション のインストール」に少し載せているので、良かったら参考にしてください。
無料ですので是非ともSQLの学習に役立ててください。
SSMSの使い方
SSMS は、SQL のインスタンスを構成したり、状況を監視したり、データベースを管理するためのツールで、アプリケーションで使われるクエリとスクリプトを作成したりすることもできます。
なので非常に多岐にわたる使用方法が有ります。
ここでは、SQLの学習のみに焦点をあてて、クエリを書くところまで説明します。
SSMS 起動
スタートから「Microsoft SQL Server xxxx」もしくは「Microsoft SQL Server Tools xx」を探し展開します。
その中から「Microsoft SQL Server Management…」を探しクリックします。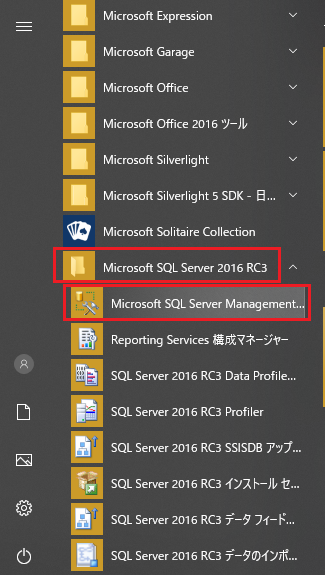
もしくは、検索にキーワード「ssms」を入力して「Microsoft SQL Server Management Studio」をクリックします。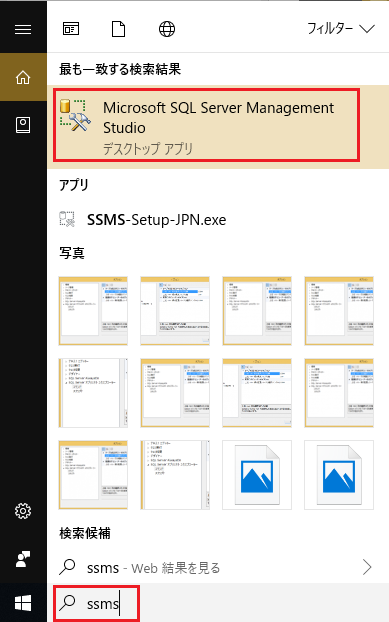
新しいクエリ画面の表示
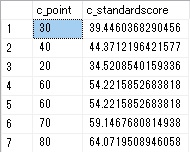
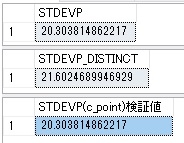
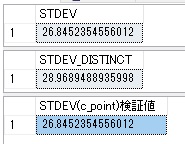
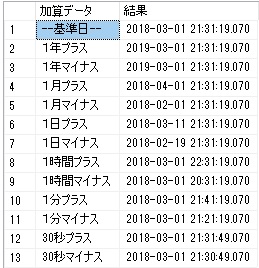
データベースのデータを操作するには「クエリ」を書きます。
SQL言語でデータ操作を行う文をクエリ画面に書きます。
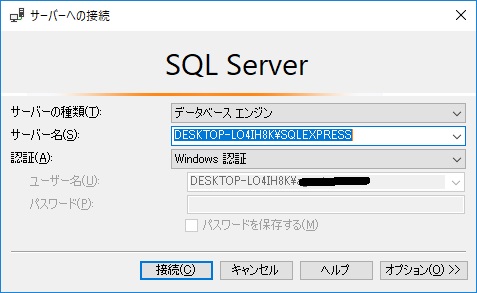
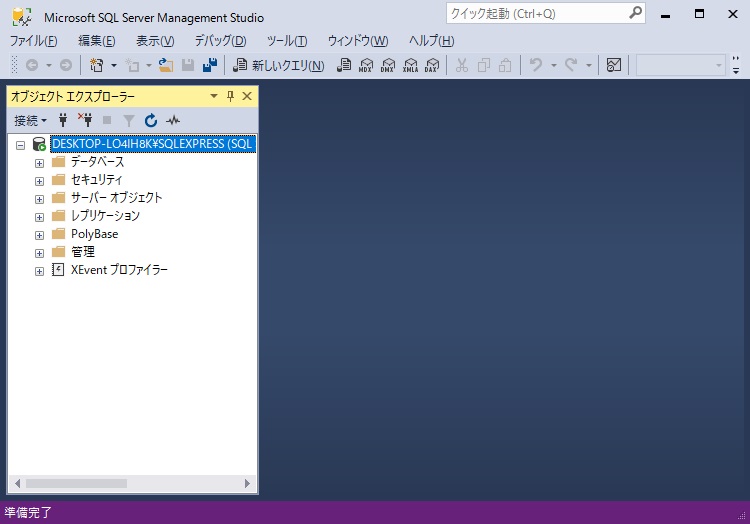
SSMSを立ち上げると下のような画面が表示されます。
サーバーを確認して、データベースを展開します。
データベースをクリックして選択します。
メニューバーの「新しいクエリ(N)」をクリックします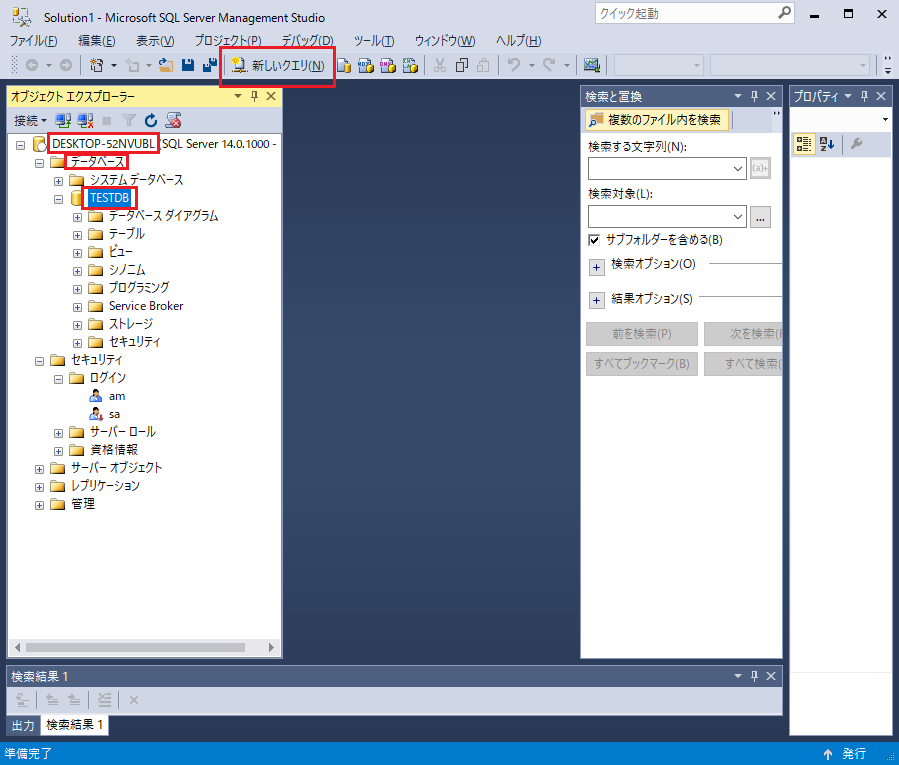
クエリの入力と実行
大きな赤枠の部分にSQL文を記述します。
記述し終わったら、左上の「!実行」ボタンをクリックして、SQL文を実行します。
正常に処理されると、下に結果が表示されます。
エラーが発生するとその原因が表示されます。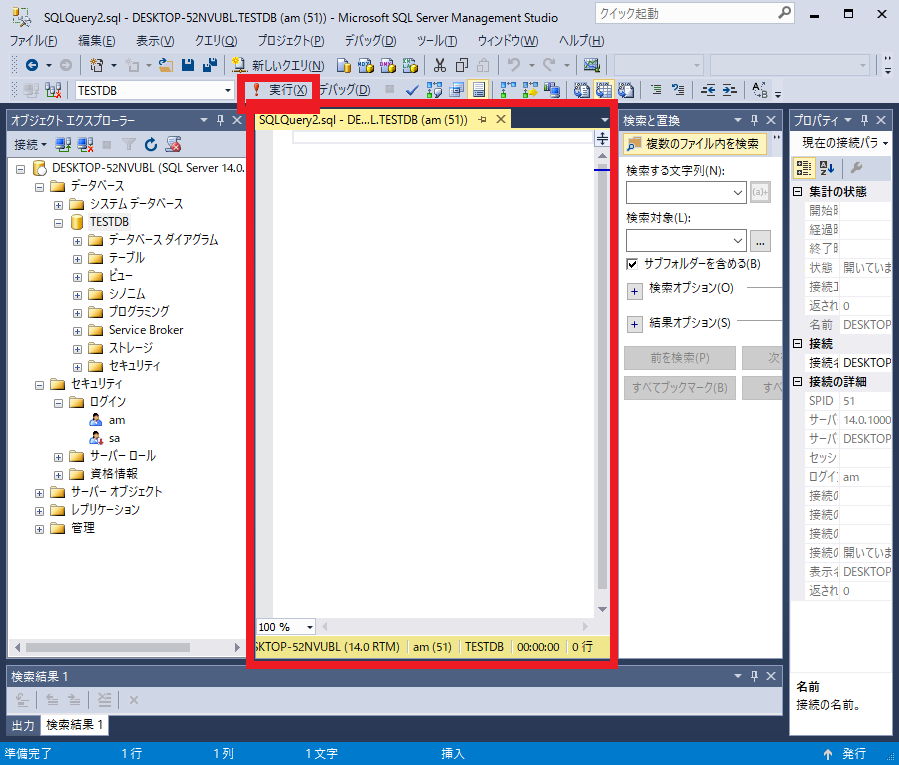
以上、SSMSとは、でした。