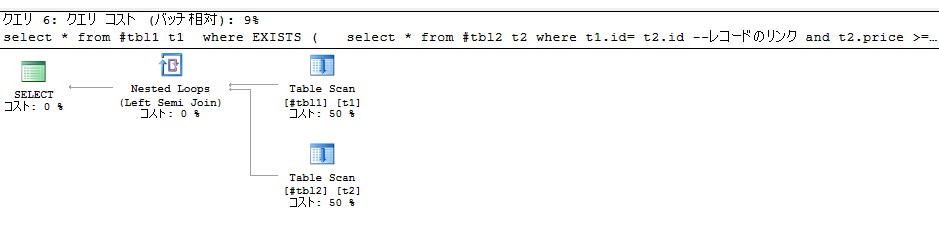
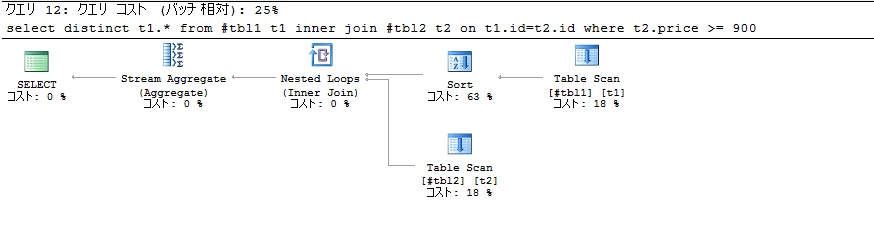
今日はSQL SERVERのPivotに付いて使い方例を開発備忘録しておきます。
PivotはEXCELで良く集計に使われる関数です。
一般的にデータは正規化されて項目重複のない状態で保存されます。
例えば、売り上げは、日時、店舗CD、商品CD、個数、他と、店舗マスタ、商品マスターのような状態で保存されます。
人が見やすいデータは正規化されたデータと異なり、
例えば、同じ売り上げでも、日付、店舗名、商品名、個数、合計価格となります。
上の販売データの羅列を見せられても、人は売上状況を把握しづらいものです。
もっと言うなら、「森全体 ⇒ 森の一部 ⇒ 木 ⇒ 幹 ⇒ 枝 ⇒ 葉」のようにマクロなデータからミクロに向かう方が把握分析しやすいと言われています。
Pivotは個々の葉のレコードを寄り集めて、枝や幹、木、森の一部のような集計したデータにしてくれる関数です。
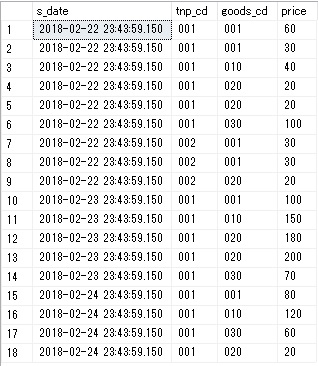
下のSQL例は、日時、商品CD、販売額のデータを
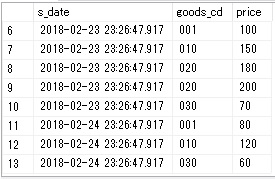
pivotー販売データテーブル
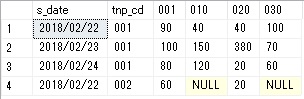
日付を行に商品を列に金額を合計した表をPivot関数を利用して返すようにしたものです。
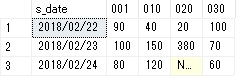
販売データpivotテーブル
また、PivotのIN句の中ではサブクエリが使用できないようなので、動的にSQLを作ってexecSQLで実行しています。
変数テーブルを使用しているため、execSQLでちょっと面倒になっていますが、本来はこんなことにならないので。。。勘弁してください。
declare @tbl1 table(s_date datetime, goods_cd nvarchar(9), price int)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE()-1, '001', 60)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE()-1, '010', 40)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE()-1, '020', 20)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE()-1, '030', 100)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE()-1, '001', 30)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE(), '001', 100)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE(), '010', 150)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE(), '020', 180)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE(), '020', 200)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE(), '030', 70)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE()+1, '001', 80)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE()+1, '010', 120)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE()+1, '030', 60)
select * from @tbl1
/*pivot*/
select * from (select convert(VARCHAR, s_date, 111 ) as s_date, goods_cd, price from @tbl1) S1 pivot (sum([price]) for [goods_cd] in ([001], [010], [020], [030])) T1
--IN句を動的に作ろうとするとエラーになる
--in ([001], [010], [020], [030])が動的に作れない。。。
--select * from (select convert(VARCHAR, s_date, 111 ) as s_date, goods_cd, price from @tbl1) S1 pivot (sum([price]) for [goods_cd] in (select distinct goods_cd from @tbl1)) as T
--ので、そこで変数内にSQLを書き、実行する。
--IN句を動的に作り、@goods_listに格納する
declare @goods_list nvarchar(128)
select @goods_list=replace(REPLACE((SELECT distinct goods_cd AS [kugiri]
from @tbl1
for xml path ('')), '</kugiri>', '],'), '<kugiri>','[')
set @goods_list=substring(@goods_list,0,len(@goods_list))
--実行SQLクエリ作成
--execでは、変数テーブルが読めない(アクセスできない)ため、ここにも変数テーブルを追加(通常のテーブルならこんな必要はないです)
declare @sql nvarchar(2048)
set @sql =
'
declare @tbl1 table(s_date datetime, goods_cd nvarchar(9), price int)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE()-1, ''001'', 60)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE()-1, ''010'', 40)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE()-1, ''020'', 20)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE()-1, ''030'', 100)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE()-1, ''001'', 30)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE(), ''001'', 100)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE(), ''010'', 150)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE(), ''020'', 180)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE(), ''020'', 200)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE(), ''030'', 70)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE()+1, ''001'', 80)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE()+1, ''010'', 120)
insert into @tbl1 (s_date,goods_cd,price) values (GETDATE()+1, ''030'', 60)
select * from (select convert(VARCHAR, s_date, 111 ) as s_date, goods_cd, price from @tbl1) S1 pivot (sum([price]) for [goods_cd] in (' + @goods_list + ')) T1
'
-- SQLクエリの実行
exec sp_executesql @sql;
上のデータに店舗を入れた場合は、以下のようになります。
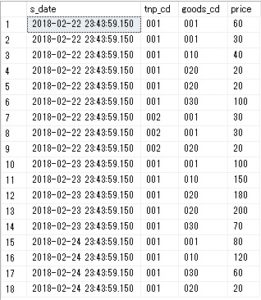
pivotー販売データテーブル-店舗CD付き
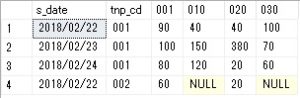
販売データpivotテーブル店舗CD付き
declare @tbl1 table(s_date datetime, tnp_cd nvarchar(5), goods_cd nvarchar(9), price int)
insert into @tbl1 (s_date,tnp_cd,goods_cd,price) values (GETDATE()-1, '001', '001', 60)
insert into @tbl1 (s_date,tnp_cd,goods_cd,price) values (GETDATE()-1, '001', '001', 30)
insert into @tbl1 (s_date,tnp_cd,goods_cd,price) values (GETDATE()-1, '001', '010', 40)
insert into @tbl1 (s_date,tnp_cd,goods_cd,price) values (GETDATE()-1, '001', '020', 20)
insert into @tbl1 (s_date,tnp_cd,goods_cd,price) values (GETDATE()-1, '001', '020', 20)
insert into @tbl1 (s_date,tnp_cd,goods_cd,price) values (GETDATE()-1, '001', '030', 100)
insert into @tbl1 (s_date,tnp_cd,goods_cd,price) values (GETDATE()-1, '002', '001', 30)
insert into @tbl1 (s_date,tnp_cd,goods_cd,price) values (GETDATE()-1, '002', '001', 30)
insert into @tbl1 (s_date,tnp_cd,goods_cd,price) values (GETDATE()-1, '002', '020', 20)
insert into @tbl1 (s_date,tnp_cd,goods_cd,price) values (GETDATE(), '001', '001', 100)
insert into @tbl1 (s_date,tnp_cd,goods_cd,price) values (GETDATE(), '001', '010', 150)
insert into @tbl1 (s_date,tnp_cd,goods_cd,price) values (GETDATE(), '001', '020', 180)
insert into @tbl1 (s_date,tnp_cd,goods_cd,price) values (GETDATE(), '001', '020', 200)
insert into @tbl1 (s_date,tnp_cd,goods_cd,price) values (GETDATE(), '001', '030', 70)
insert into @tbl1 (s_date,tnp_cd,goods_cd,price) values (GETDATE()+1, '001', '001', 80)
insert into @tbl1 (s_date,tnp_cd,goods_cd,price) values (GETDATE()+1, '001', '010', 120)
insert into @tbl1 (s_date,tnp_cd,goods_cd,price) values (GETDATE()+1, '001', '030', 60)
insert into @tbl1 (s_date,tnp_cd,goods_cd,price) values (GETDATE()+1, '001', '020', 20)
select * from @tbl1
/*pivot*/
select * from (select convert(VARCHAR, s_date, 111 ) as s_date, tnp_cd, goods_cd, price from @tbl1) S1 pivot (sum([price]) for [goods_cd] in ([001], [010], [020], [030])) T1
以上、今日はSQL SERVERのPivotに付いて使い方例を開発備忘録でした。