robots.txt の使い方。。。の前に
先日、『IX Web Hosting ハッキングされた!』に書いた通りハッキングされたのですが、その後何も起こらず平穏な日々に戻っています。
ハッキングされたのは「趣味のブログ」サイトで被害自体はどうってことのないものでした。
勝手に時計を売るページを引っ張ってくるページを作られたのですが、参照先もどこかの企業のホームページを使っていました。
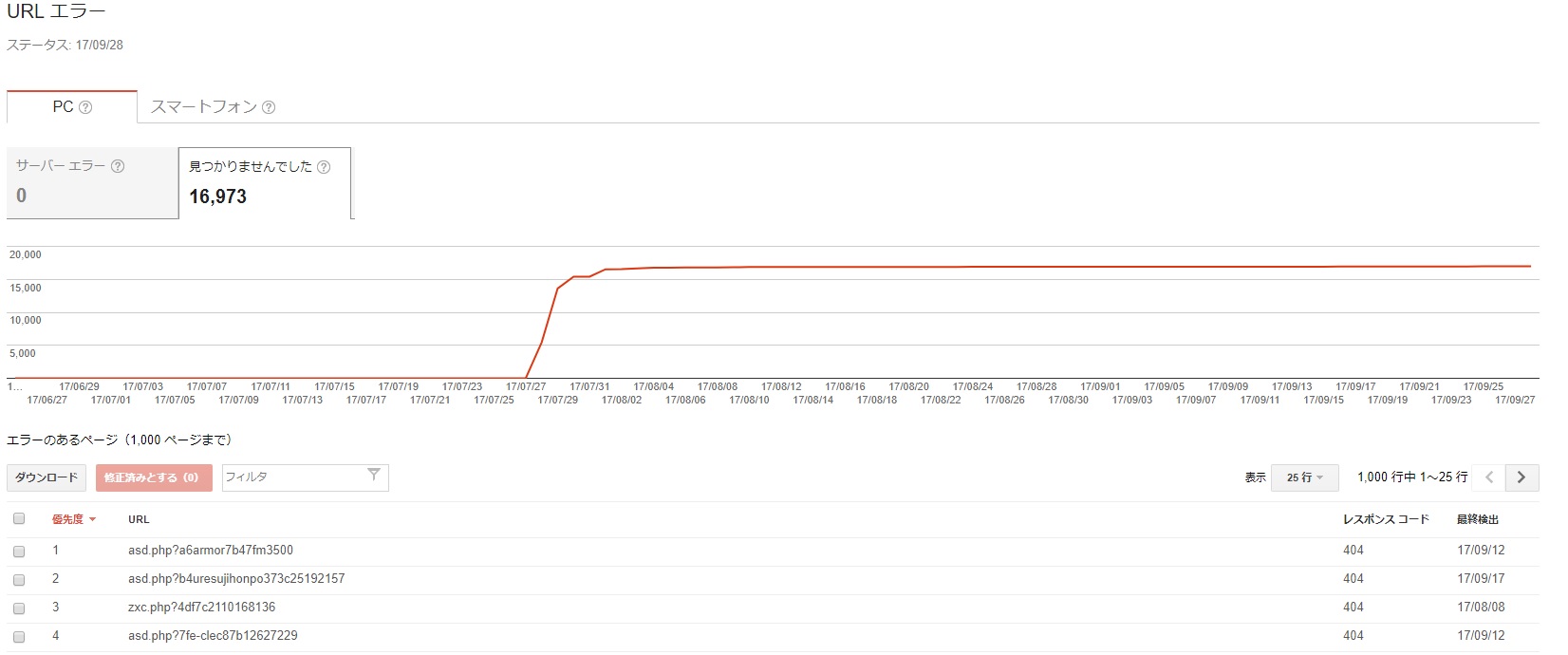
で、問題は、Googleの「Search Console」のクロールエラーが一向に減らないってことです。
404エラーなので、「Googlebot はこの URL をクロールできませんでした。この URL が存在しないページを指していることが原因です。一般に、404 が発生しても検索結果でのサイトの掲載順位が低下することはありませんが、このエラー情報を使用してユーザーの利便性を向上させることができます。」とある通り、影響はないのですが、気持ち悪くて。。。
{kind=link}
robots.txt の使い方
そこで、robots.txt の出番です。
robots.txt とは、Google や Bing などのロボット型検索エンジンに対する命令(依頼?)を記述するためのファイルです。
例えば自分のページの一部を、検索エンジンのデータベースに登録されないように命令(依頼?)をします。
命令には、
・対象:User-agent
・許可:Allow
・拒否:Disallow
・通知:Sitemap
の記述があります。
User-agent
GooglebotやBingbotなど命令(依頼?)したいクローラーを指定します。
基本的には、「*」で全てのクローラーを対象にします。
Allow
クローラーの訪問をブロックしないディレクトリやページを指定します。
基本的には、ブロックしないディレクトリやページを許可する方法はとらないので、使わないケースが多いです。
ディレクトリを指定すると配下のページにも影響を及ぼします。
Disallow
クローラーの訪問をブロックするディレクトリやページを指定します。
基本的には、検索対象にしたくなページを指定することになりますが、写真などのディレクトリをインデックスされたくない場合などに使います。
「/」でサイト全体を、「/dir/」でdirディレクトリ以下全てのページを指定したことになります。
「/*.jpg$」で全てのjpgファイルに対した指定も可能です。
Sitemap
sitemap.xmlの場所(URL)をクローラーに通知します。
URLは絶対パスで記述します。
今回の robots.txt
User-Agent: * Disallow: /asd.php Disallow: /zxc.php Disallow: /qwe.php
全てのbotに対して、
asd.php、zxc.php、qwe.phpへのインデックスを拒否するように依頼をしました。
「Search Console」のrobots.txt テスター
robots.txt テスターツールを使用すると、robots.txt ファイルでサイト内の特定の URL に対して Google のウェブクローラがブロックされているかどうかを確認できます。
一応、『robots.txt を使用して URL をブロックする robots.txt テスターで robots.txt をテストする』を貼っておきます。
具体的な使い方がわからない時は、robots.txt テスターでググると出てきます。
これでしばらくすると、エラー数も落ち着いてくると思うのですが。。。
減ってきたらまたここに追記します。
あっ、効果なくても報告します。