Google アナリティクスのトラッキングコードを張り付けても上手く認識されていない状況の報告です。約24時間経過しましたが「ステータス: トラッキングがインストールされていません」と出たままです。
レポート>ユーザー>サマリー画面でも全くデータが入っていませんが2日間くらい反映が遅くなるんでしたよね?ここを見ても当てにならないですよね。
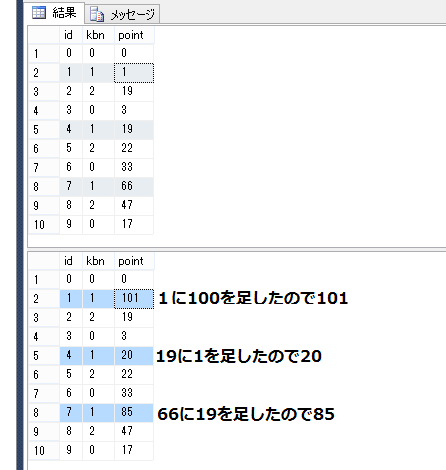
結果を先にお話ししておくと、設置してから48時間後くらいに正常にトラッキングコードが認識され受信するようになりました。
途中TagManager経由で試すなどしてみましたが、結果は同じでした。ちゃんとトラッキングコードが設定できてるなら、放置しておいても大丈夫のようです。
ということで、同じような人がそのうち現れた時の参考までに、経過状況を書き連ねます。
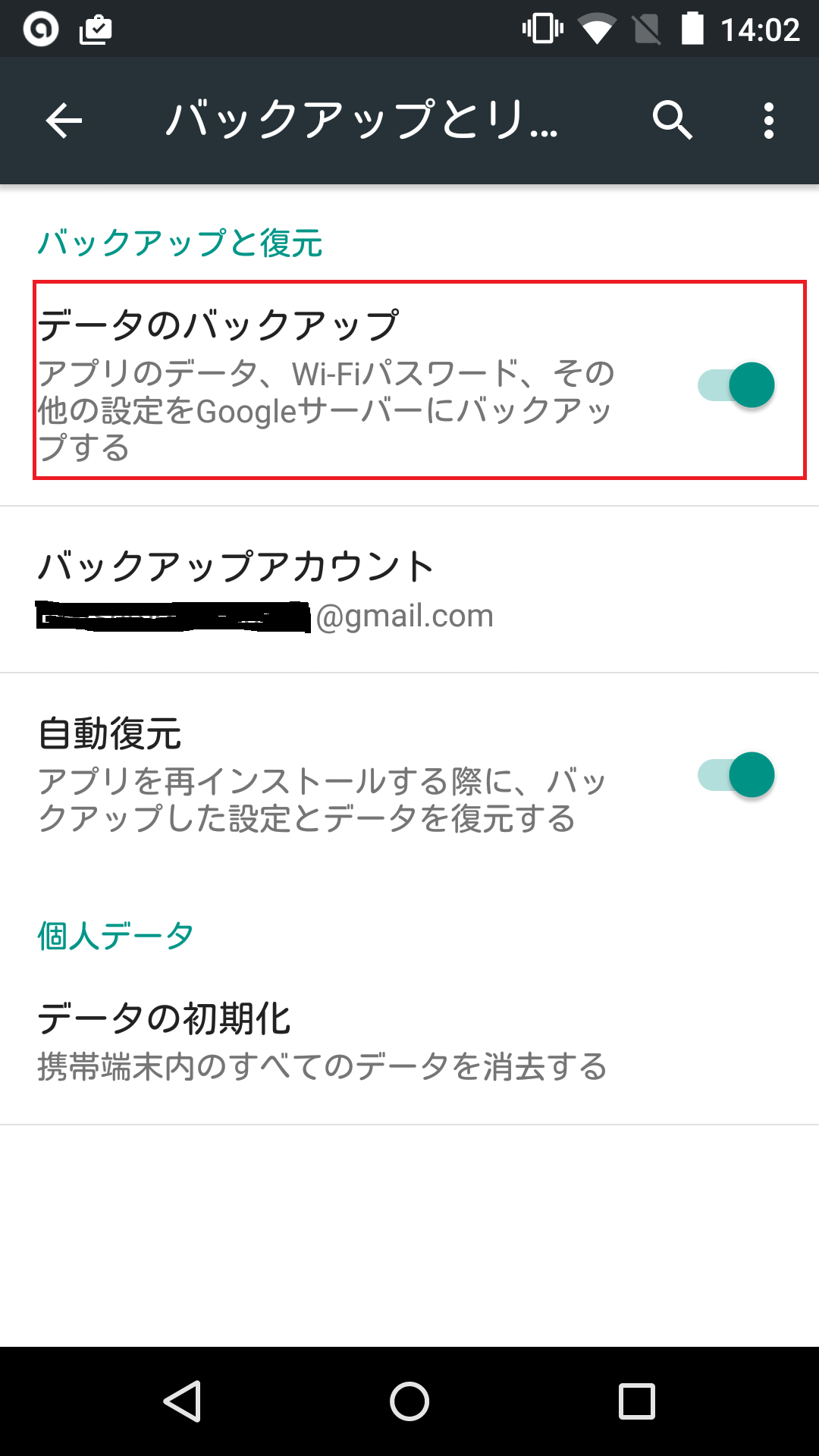
トラッキングコード張付けについて
トラッキングコードheadタグの一番下に張り付けました。
張付け方は以前にも数回行ったことが有るので間違いないと思います。
また、Webサイト(ブログサイト)を表示して目視でもトラッキングコードを確認しています。
その後2時間程度放置後
すぐには反映されない?ことも有るのかもと考え2時間程度放置しました。
それでも、やはりダメでした。
そこでどこからもアクセスが無いので 「データを受信しています」とならないのかも、、、と考え、スマホのWifiを切ってドコモに繋いで表示して見ることに。
ダメでした。
レポート>リアルタイム>サマリーにも反応なし。ここはリアルタイムでデータが入ると思うのですが、ダメでした。
「データを受信しています」にならず、「トラッキングがインストールされていません」のままです。
ググって情報収集してみる
「トラッキングがインストールされていません」でググってみましたが、特に有効な情報は得られませんでした。
ただ単に張り付けるだけなので、そんなに難しくないですもんね。当然と言えば当然かと。。。
プロパティを作り替えると上手く行くとの報告が有ったので、試してみましたがダメでした。
目視でトラッキングコードを確認しましたが、インストールされていないと出ます。
同じWebサイト(ブログサイト)に2つのトラッキングコードが付いてしまいました。
タグマネージャーを利用してみる
仕方なくタグマネージャー(Tag Manager)なるものを使用してみることにしました。タグマネージャって良く分からないんですよね。
間違って認識しているかもしれないんですが、タグマネージャのタグを張り付ければ、他のタグは張らなくて良くて、例えばアナリティクスのタグをタグマネージャーで認識させてやればそれでOKなんだろ。。。と言うもの?
それから、マウスの動きを捉えれるので、ちゃんと設定すればいろな情報が貰える仕組みを持ってる。。。のかな?
で、とりあえずアカウントを作って設定して、後から追加したアナリティクスのトラッキングIDを設定して、プレビュー・デバッグでアナリティクスのタグがどうなってるか確認しました。
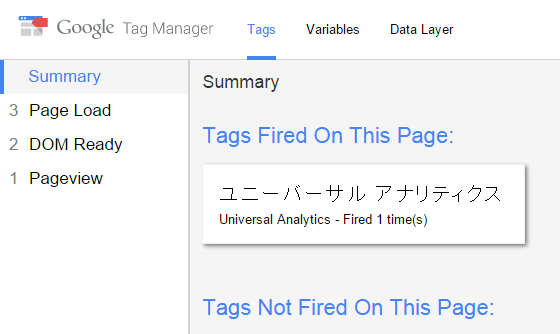
ユニバーサル アナリティクスが「Tags Fired On This Page」に出てますよね?
クリックして中身を更に確認
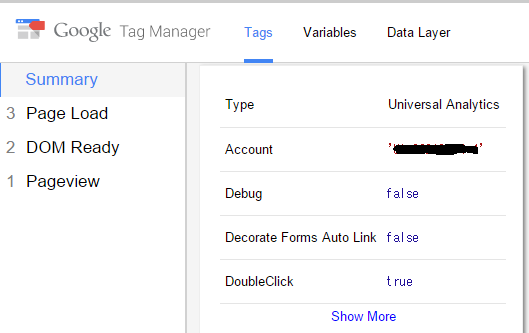
ちゃんと設定したUniversal Analyticsが表示されています。
その後12時間程度放置後(最初の設置から26時間くらい)
状況は変わりません。
タグマネージャーで設定してもアナリティクスのトラッキングコードは変わらないのかな?
そう考えると、今しばらく待ってみるしか無いですね。
一応、レポート>リアルタイム>サマリーでチェックしてみることに。
最初に作成したプロパティに反応有りました!!
タグマネージャー経由はやり方が違っているのか、反応なし・・・
しかし、反応の有ったプロパティのトラッキングのステータスは「ステータス: トラッキングがインストールされていません」のままです。

最終確認日が太平洋夏時間(PDT)で出てますね。16時間差でしたっけ?
22:12+16=1日 14:12
だいたい合ってます。つい先ほどレポート>リアルタイム>サマリーで反応が有ったのにダメってことですね。
実に厄介な表示ですね。
更に11時間くらい経過
現在の状況です。

ステータスは「ステータス: トラッキングがインストールされていません」のままです。
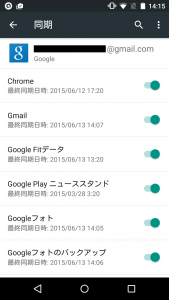
しかし、レポート>ユーザー>サマリーにデータが入ってきてます。これってウェブマスターツールのデータが入ってきてるだけじゃないですよね?
実際はトラッキング情報が入ってきてるけど、ステータスだけがダメってことなのかな?
設置48時間後くらい
現在の状況です。
正常になった模様です。
ステータス役割がいい加減だったってことでしょうか?
とりあえず、これで調査終了です。
今回はGoogle アナリティクスの「ステータス: トラッキングがインストールされていません」が気になって定期的に確認しに行ってみました。
今までの経験では直ぐにステータスは反映していたのですが、今回は時間が掛かりました。
このようなケースも有るのですね。勉強になりました。

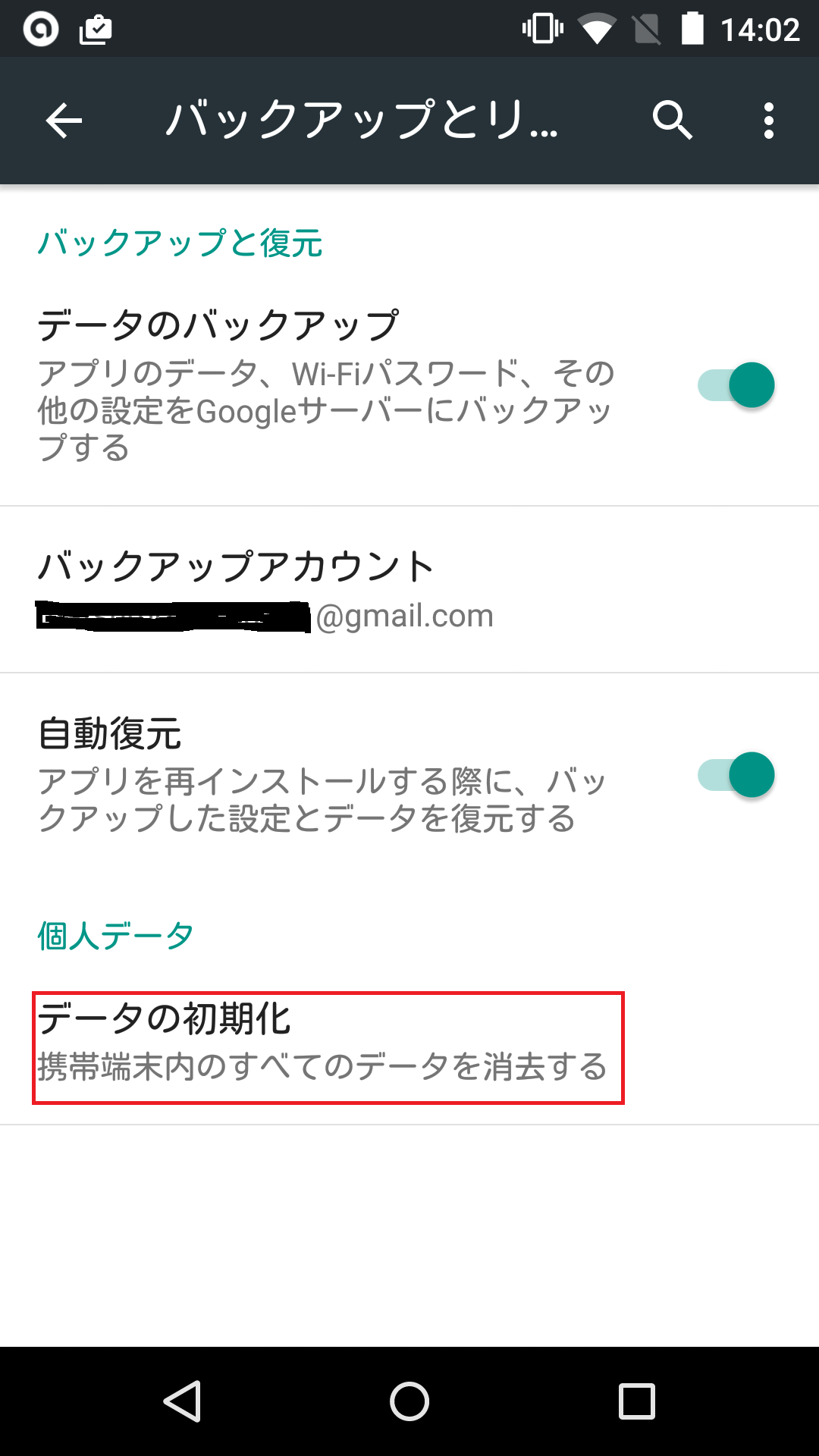
 android スマホを 新しいスマホへデータ移行 することになりました。
android スマホを 新しいスマホへデータ移行 することになりました。